-
분산 시스템을 위한 유일 ID 생성기 설계책/misc 2022. 7. 9. 00:04
분산 시스템을 위한 유일 ID 생성기 설계
‘auto_increment’ 속성이 설정된 RDB의 기본 키를 쓰면 되지 않을까? 라고 생각할 수 있다.
- 분산 환경에서 이 접근법은 통하지 않는다.
- DB 서버 한 대로는 그 요구를 감당할 수 없다.
- 여러 데이터베이스 서버를 쓰는 경우에는 지연 시간을 낮추기가 무척 힘들 것이다.
요구사항
- 책에서의 요구사항에 맞춰 구현해보자.
- ID는 유일해야 한다.
- ID는 숫자로만 구성되어야 한다.
- ID는 64비트로 표현될 수 있는 값이어야 한다.
- ID는 발급 날짜에 따라 정렬 가능해야 한다.
- 초당 10,000개의 ID를 만들 수 있어야 한다.
개략적인 설계안
다중 마스터 복제(multi-master replication)

DB의 auto_increment 기능을 활용한다. 다만 다음 ID 값 구할 때 1을 증가시키는게 아니라, k(DB 서버의 수)만큼 증가시킨다.
단점:- 여러 데이터 센터에 걸쳐 규모를 늘리기 어렵다.
- ID의 유일성은 보장되겠지만 값이 시간 흐름에 맞춰 커지도록 보장할 수는 없다.
- 서버를 추가하거나 삭제할 때도 잘 동작하게 만들기 어렵다.
UUID(Universally Unique Identifier)
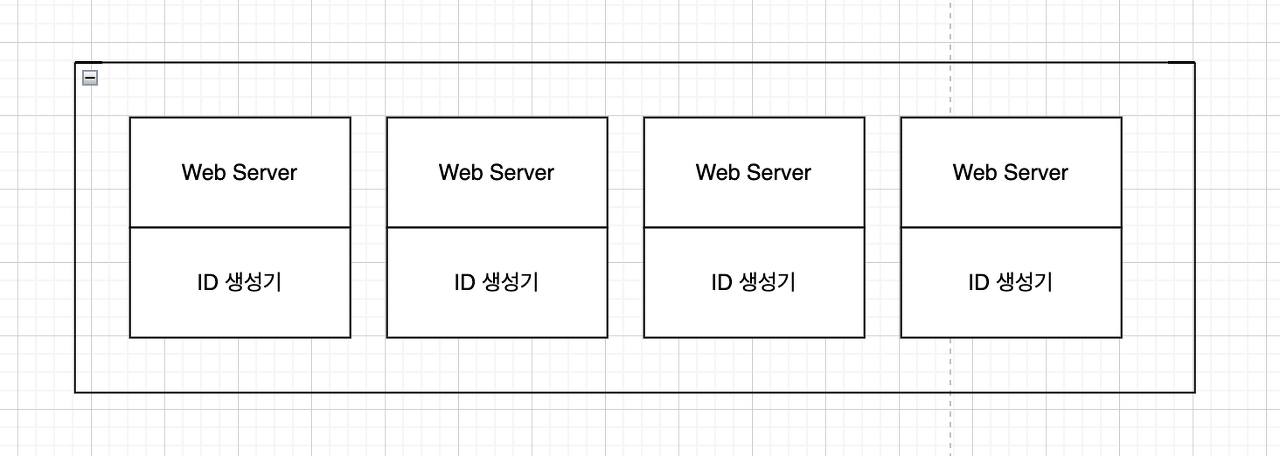
UUID는 컴퓨터 시스템에서 저장되는 유일하게 식별하기 위한 128비트짜리 수다. f18aece2-b984-4ae3-a03e-ad37c5829e98 이런 형태이다. 각 웹 서버는 별도의 ID 생성기를 사용해 독립적으로 ID를 만들어낼 수 있다.
장점:- 단순하다.
- 동기화 이슈가 없다.
- 각 서버가 자기가 쓸 ID를 알아서 만드는 구조이므로 규모 확장이 쉽다.
단점:
- ID가 128비트로 길다.
- ID를 시간순 정렬할 수 없다.
- 숫자가 아닌 값이 포함될 수 있다.
티켓 서버(ticket server)

이 아이디어의 핵심은 auto_increment 기능을 갖춘 DB 서버, 즉 티켓 서버를 중앙 집중형으로 하나만 사용하는 것이다.
플리커(Flickr)는 분산 기본 키(distributed primary key)를 만들어 내기 위해 이 기술을 이용했다고 한다.
장점:- 유일성이 보장되는 숫자로만 구성된 ID를 쉽게 만들 수 있다.
- 구현하기 쉽고, 중소 규모 애플리케이션에 적합하다.
단점:
- 티켓 서버가 SPOF(Single-Point-of-Failure)가 된다. 이 서버에 장애가 발생하면 모든 시스템이 영향을 받는다. 이 이슈를 피하려면 티켓 서버를 여러 대 준비해야 하는데, 그렇게 하면 데이터 동기화 같은 문제가 새로운 문제가 발생한다.
트위터 스노플레이크(twitter snowflake)

사인(sign) 비트: 1비트를 할당한다. 나중을 위해 유보해둠. 음수와 양수 구별에 사용할 수 있을 듯
타임스탬프(timestamp): 41비트 할당. 기원 시간(epoch) 이후로 몇 밀리초가 경과했는지 나타내는 값이다.
기준 시점을 1970년 1월 1일 자정으로 할 수도 있으나 더 많은 시간 동안 사용할 수 있도록 트위터 스노플레이크 구현에서 시작시간을 1288834974657 (Nov 04, 2010, 01:42:54 UTC) 값을 사용한다.
데이터센터 ID: 5비트 할당. 따라서 2^5 인 32개의 데이터 센터 지원 가능
서버 ID: 5비트 할당, 32개 서버 사용 가능
일련번호: 12비트 할당, 각 서버에서는 ID 생성 시마다 일련번호를 1씩 증가시킨다. 1밀리초가 경과할 때마다 0으로 리셋된다.상세 설계
요구사항을 만족할 수 있는 트위터 스노플레이크 접근법을 사용하여 상세한 설계를 진행해보자.

데이터센터 ID, 서버 ID는 시스템이 시작할 때 결정되며, 일반적으로 시스템 운영 중에는 바뀌지 않는다.
데이터센터 ID나 서버 ID를 잘못 변경하게 되면 ID 충돌이 발생할 수 있으므로 신중해야 한다.
타임스탬프나 일련번호는 ID 생성기가 돌고 있는 중에 만들어지는 값이다.타임스탬프
시간이 흐를수록 점점 큰 값을 갖게 되므로, 결국 ID는 시간순 정렬이 가능하게 될 것이다.
이진 표현 형태의 41비트를 어떻게 UTC 시각으로 추출하는지 보자.
41비트로 표현할 수 있는 타임스탬프의 최댓값은 2^41-1 ⇒ 대략 69년이다.
따라서 이 ID 생성기는 69년 동안만 정상 동작하므로 69년이 지나면 기원 시각을 바꾸거나 ID 체계를 다른 것으로 이전하여야 한다.일련번호
2^12 ⇒ 4096개의 값을 가질 수 있다. 어떤 서버가 같은 밀리초 동안 하나 이상의 ID를 만들어 낸 경우에만 0보다 큰 값을 갖게 된다.
추가 논의 가능
- 시계 동기화(clock synchronization): 키워드 NTP(Network TIme Protocol)
- 각 절(section)의 길이 최적화: ex. 동시성이 낮고 수명이 긴 애플리케이션이라면 일련번호 절의 길이를 줄이고 타임스탬프 절의 길이를 늘릴 수 있음.
- 고가용성(high availability): ID 생성기는 필수 불가결(mission critical) 컴포넌트이므로 아주 높은 고가용성을 제공해야 한다.
참고: 가상 면접 사례로 배우는 대규모 시스템 설계 기초
'책 > misc' 카테고리의 다른 글
1장. 타입스크립트 알아보기 (0) 2022.07.17 알림 시스템 설계 (0) 2022.07.09 안정 해시 설계 (2) 2022.06.21 처리율 제한 장치의 설계 (3) 2022.06.19 3장. HTTP 메시지 (0) 2022.05.02